Recent searches
Search options


Got #DeepSeek Coder 33B running on my desktop's #AMDGPU card with #ollama.
First off, I tested its ability to generate and understand #Rust code. Unfortunately, it falls into the same confusion of the smaller 6.7B model.
https://gist.github.com/codewiz/c6bd627ec38c9bc0f615f4a32da0490e
#ollama #llm #deepseek
To be completely fair, thread safety and atomics are advanced topics.
Several humans I have interviewed for engineering positions would also have a lot of trouble answering these questions. I couldn't write this code on a whiteboard without looking at the Rust library docs.
The main problem here is that the model is making up poor excuses to justify Arc<AtomicUsize>, showing poor reasoning skills.
Larger models like #GPT4 should do better with my #Rust #coding questions (haven't tried yet).
Indeed, #GPT4o nails my Rust + thread safety questions:
https://chatgpt.com/share/2f146510-d5d6-49b6-82fb-b8443666c06b
Google's Gemini Pro performs even worse than the opensource models running on my modest Linux desktop:
https://g.co/gemini/share/cdec7f5a6c5c
Missing from the chat log, is the last response in the image below 
I don't have Gemini Advanced / Ultra. Is it a bit smarter than this?
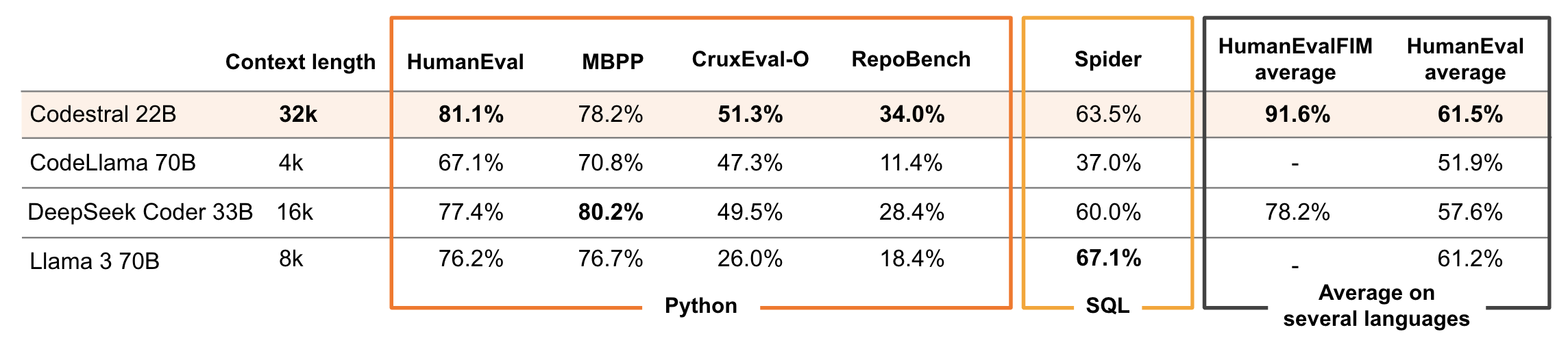
Today I tried running Codestral, a 22B parameter LLM tuned for coding by Mistral AI.
With my Rust mock interview questions, it performed better than all other offline models I tried so far.
https://paste.benpro.fr/?4eb8f2e15841672d#DGnLh3dCp7UdzvWoJgev58EPmre19ij31KSbbq8c85Gm
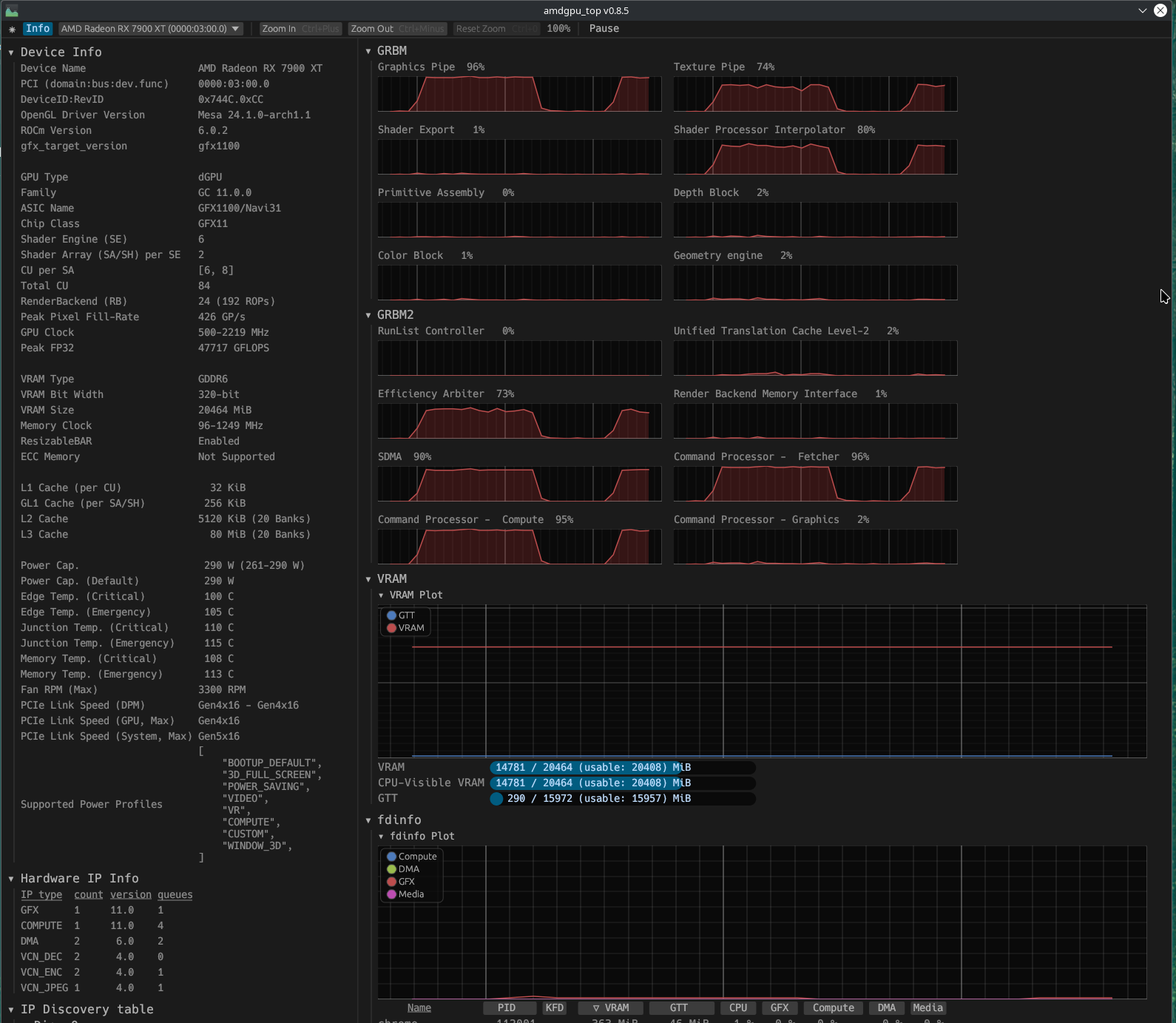
My AMD GPU running Codestral, a 22B parameter LLM.
The gaps in resource usage occur when the model is waiting for the next prompt from me.
With this setup, a response of 543 tokens took about 14.3 seconds (38 tokens/s).

@codewiz What's the memory size of that amd gpu?